Note: I wrote a more politically correct version of this piece for Tech Policy Press
If you ever moved to an alternative service or app, and struggled with how to not start from scratch, you already have experience with data portability. Or its absence).
Being able to bring the data you created, be it photos from iCloud, notes from Evernote, or your reading history on Goodreads, to an equivalent service somewhere else is both an obvious right that should be afforded to users and an endless pit of disappointment when it comes to reality.
You would assume that moving data that we’ve been able to transfer from one device to another for decades using USB sticks, floppy disks and CD-ROM would be trivial. Yet in the digital age, it seems to be harder than ever if said data is something you generated or imported into an app or service. Especially rent can be extracted from it. And ever more so if said app or service is offered by a Big Tech company.
The EU tried to tackle this with the General Data Protection Regulation (GDPR) with a right to data portability developed under article 20(1) and 20(1), with the goal of giving users control over their data. More recently, the Digital Markets Act (DMA) Article 6(9) created a more binding obligation for gatekeepers (read Big Tech companies) to provide data portability, this time to foster competition by making it easier for users to move services.
While enforcement of data portability has been limited under GDPR, I think it’s interesting to look at how it could be applied to generative AI, notably under the DMA. Should our tech overloads be right and we all end up only interfacing with AI agents in the future (something doubly horrendous as it is would likely go along with Big Tech companies maintaining their dominance), it would be most appreciated to have the option to easily switch to another service. Who knows, you might feel a change of heart and suddenly decide to support a different tech billionaire?
Joke aside, the value in data portability for AI agent could be high as these systems are increasingly being developed to be our main interface with technology (with the risks to privacy and security it entails). This means that the data processed by those services would not only be our interactions with them, via text, voice, image, the data generated from it (memories, profiles, etc.), but also the different connections it maintains with other digital services, such as your email, local files and payment methods.
NOTE: I appreciate this can read like a nightmare scenario for certain people. AI currently has Big Tech stamped all over it and that doesn’t make for an optimistic future. I hear you. But I also have hopes that we can get the benefits of such a technology without having to comprise our privacy, or soul, with Open Source solutions running local models and embedding fine-grained control. OpenInterpreter is a first step in this direction. Jan is also quite pleasant to use. One can dream.
The good news is that the current AI agent stacks offer many opportunities to facilitate data portability. Conversations are an obvious and easy piece of the puzzle. But even what we could imagine as more advanced features like “memories” in ChatGPT or any equivalent profiling feature in AI chatbot could easily be ported given that they are basically glorified summarisation of previous conversation with inferences sprinkled on top.
Model Context Protocol (MCP) also provides another really interesting piece of the picture. Many “tools”/“connectors” and other integrations with external functions rely on MCP servers to function, and those don’t change from one service to another. The MCP Obsidian extension I use on Jan works perfectly with LM Studio. Or Claude. Or any other app that supports MCP. It would not be too far-fetched to see these extensions be part of a data portability request. Indeed, MCP extension are, for the most part, simple json config files that provide your software a choice with the instructions to download the extension, and the credentials to connect to an external service if needed. Here is an example of a Bluesky extension that allows an AI agent to post on your behalf:
{
"mcpServers": {
"bluesky-mcp": {
"command": "npx",
"args": ["-y", "@semihberkay/bluesky-mcp"],
"env": {
"BLUESKY_IDENTIFIER": "your.handle.bsky.social",
"BLUESKY_PASSWORD": "your-app-password"
}
}
}
}An example config file for the bluesky MCP server
In addition to simple text config files, permissions previously granted by the user could be ported as well. Indeed, MCP servers will usually require permission to use the tools offered by a given server. For example with a server reading your calendar like caldav-mpc, you could export what kind of permission you have given your agent for this specific server (such as read-only)
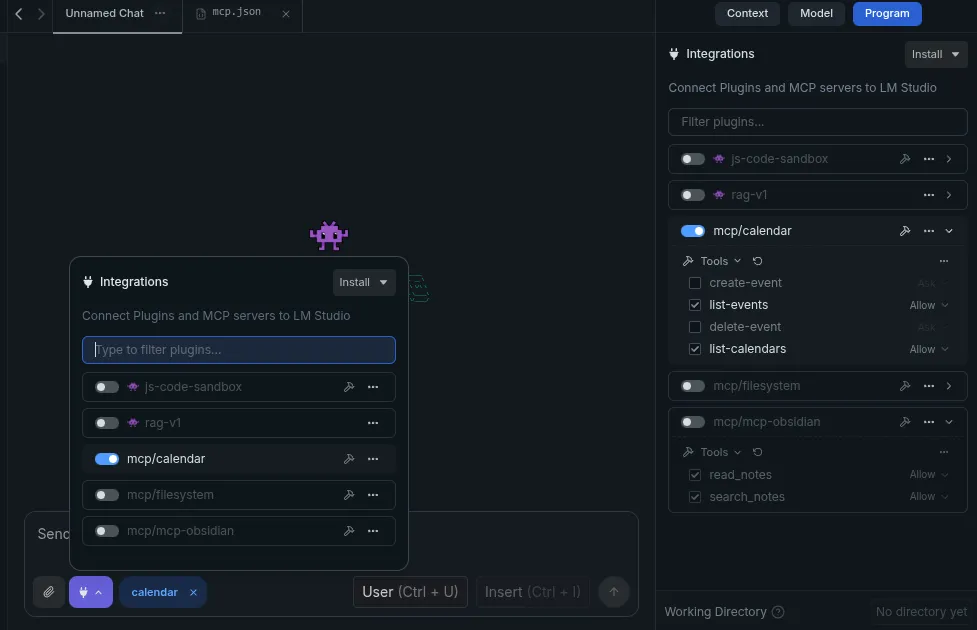
A screenshot of LM-Studio with a few a MCP connector enabled and fine-grained permissions on the right
Obviously this is all based on where things currently are, and I might update this post as things develop. But the one takeaway here is that, from where things stand, data portability looks very feasible and there are few reasons why it shouldn’t be a feature offered by major AI service providers… if we ignore the fact that they have a vested interest in keeping users locked in.
The goal of the DMA is, among other things, to prevent user lock in. And if AI agents were to fall under it (no AI product or AI first companies have currently been designated gatekeeper or core platform service), it would be necessary to make sure the data portability obligations are enforced to ensure contestability. Of course, I also wish that compliance with data portability, as defined in the GDPR, was more widely embraced by developers.
The tentation is strong in such a nascent market to want to hook users on your products, and Big Tech companies have shown that walled gardens and lack of mobility to other services played a big role in building their dominance. But the paradigm these companies have built has brought many shades of harm on users, and the lack of exit strategy for users amplified this. First because it prevented the emergence of alternatives, and second because it made leaving those services virtually impossible for less motivated users. As we speak of digital sovereignty, it’s more than time to embrace the open and interoperable nature of technologies to build a better tech future.